

どうもこんにちは、タケルです。
今後AIを活用した開発方法がもう「避けて通れない」時代になってきました。
自分もいざという時に使いこなせるようここで一度AIを基礎から学びなおしていきたいと思います。
しかし、「基本なくして応用なし」と言われるように、まずはAIがどういう仕組みで動いているのかを学んでいきます。
それでは行きましょう。
AIの歴史をざっくり学ぶ
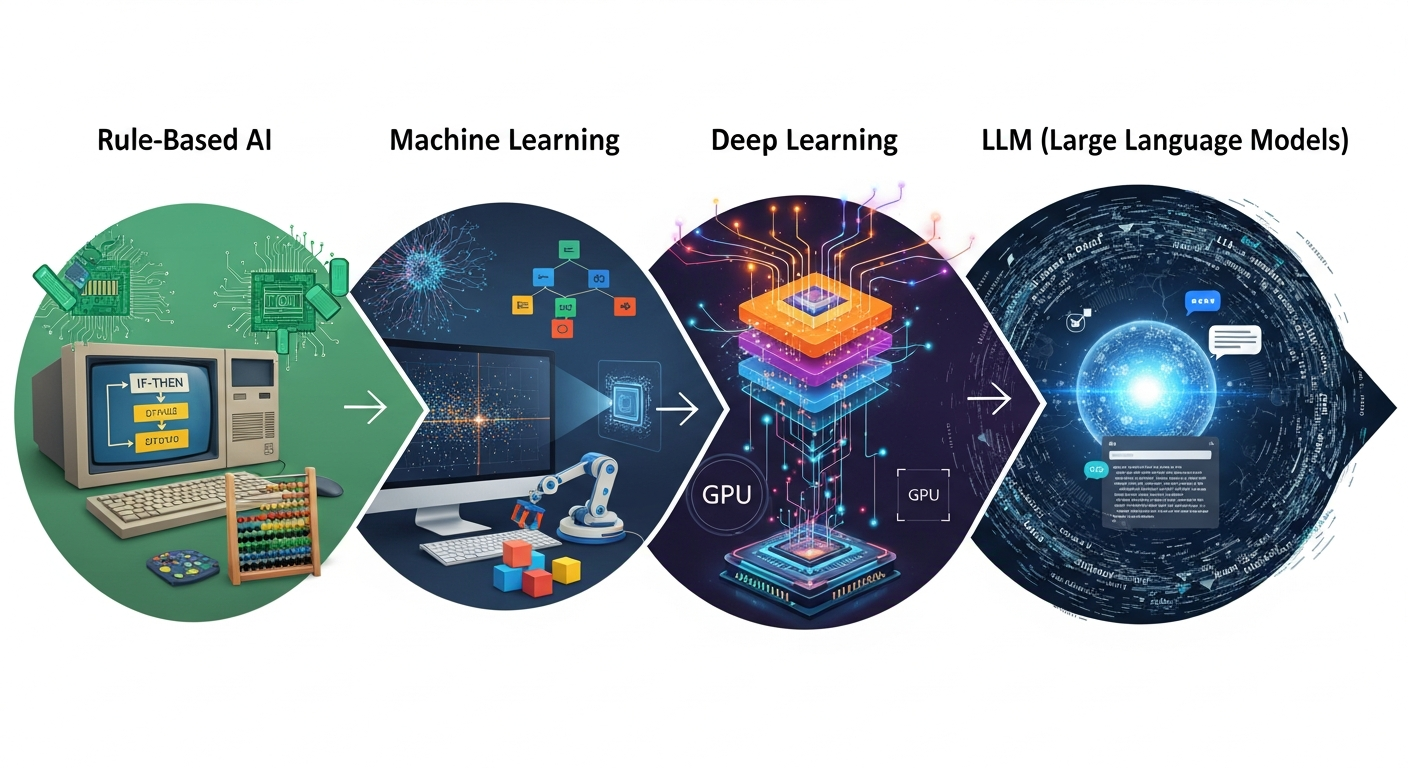
まず、今誰もが使っているChatGPTのようなLLM(大規模言語モデル)ですが、そこにいきなり到達したわけではありません。これまでのAIの歴史を振り返りましょう。
AIはおおざっぱに言うと以下の流れを経て発展してきました。
- ルールベースAI(1960〜1990年代)
- 機械学習(1990年代〜2010年前後)
- ディープラーニング(2012年ごろ〜2020年ごろ)
- LLM(大規模言語モデル)(2018年ごろ〜 / 一般普及は2022年〜)←イマココ
ルールベースAI
AIの一番初期の形は「ルールベースAI」と呼ばれるものでした。年代的には1960年~1990年代です。
ルールベースAIの特徴としては、
- 人間が「もし〇〇なら△△にする」というルール(if文)をひたすら書く
- 何かパラメータを渡したらそのルールに完全にしたがって動く
- ルールにないケースが来ると対応できない
といったものでした。イメージ的には巨大なif文のかたまり、とも言えますね。いわゆる「AI」と言いつつ、中身はかなり“きっちり決め打ちのプログラム”でした。
なので「決めたことはきっちり守るけど、想定外には弱いAI」と言えます。
製品例で言うと、昔のチャットボットとかそうだったかと思います。
ユーザーが回答する文字になにが含まれているかを判定して回答していたはずです。
機械学習
次に来たのが「機械学習」ですね。年代的には1990年代から2010年前後です。
ルールベースと違うのは、人間が「ルールそのもの」を書いていくのではなく、過去の膨大なデータを読み込ませて、「いい感じのルール」を自動で学習させる、というものでした。
例えば、
- 過去の売上データから「来月の売上」を予測する
- 過去のスパムメールの例から、「スパムかどうか」を分類する
といったことができるようになりました。
この頃のGmailの「迷惑メール判定」がまさに機械学習だったようです。
ディープラーニング
機械学習の中でも、特に強力な手法がディープラーニング(深層学習)でした。年代的には2012年ごろ〜2020年ごろですね。僕も直接触っていたわけではないですがこの頃よく近い将来ディープラーニングが来る!なんてことをよく耳にしてましたね。
ディープラーニングと機械学習はまったく別物ではなく、機械学習という大きな枠の中にある一つの手法(ニューラルネットワーク系)という位置づけです。
機械学習は、線形回帰やロジスティック回帰などいろんな手法がある総称ですが、その中でもニューラルネットワーク系だけを指すのがディープラーニングです。
しかし強いて言えば、
- (従来の)機械学習:
データから「重み(パラメータ)」を学習するが、
どんな特徴を使うか(特徴量)は人間が考えてあげる必要がある - ディープラーニング:
データから「重み(パラメータ)」を学習するだけでなく、
どんな特徴に注目すればよいか(特徴表現)もモデル自身が学習してくれる
といったところでしょう。
ディープラーニングの製品例で言うと、スマホの顔認証が代表的なところです。カメラ画像からその人の「顔の特徴」を抽出して登録します。登録された顔かどうかを判定してロック解除します。
LLM
そして、この流れの上で登場したのが「LLM(大規模言語モデル)」です。
LLMは、いきなりポッと生まれてきたわけではありません。
これまでの流れをふまえて説明すると、
- 機械学習という枠の中に「ディープラーニング(深層学習)」が生まれ、
- ディープラーニングの一つの構造として「Transformer」というモデルが登場し、
- Transformerを使って、膨大なテキストから「次に来そうな単語(トークン)」を学習させたものがLLM
という系譜になっています。
つまり、ディープラーニングがあったからこそLLMが作れた。LLMの中身も、まさにディープラーニングモデルである。
と言えます。
製品例でいうと言わずもがなChatGPTやGeminiなどが代表的なLLMですね。
LLMについて深堀りしよう
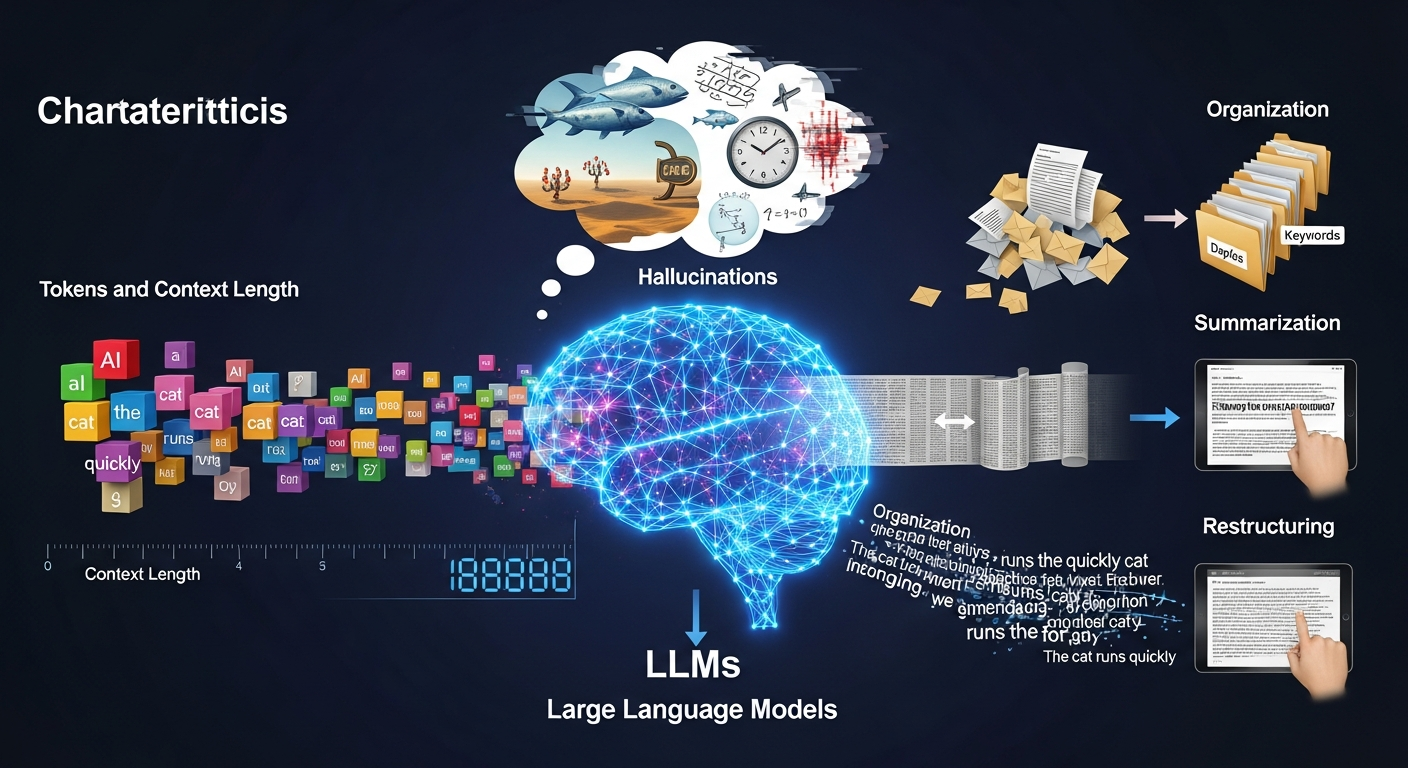
それでは、LLMについてもう少し深堀りしていきましょう。
LLMがやっていることの正体
あたかもなんでも答えているかのようなLLMですが、実際にやっていることは次に来そうな単語(トークン)の確率を予想しているだけです。
つまり
- 入力:テキスト(プロンプト)から
- 出力:次のトークンの確率分布から1つずつ選んで文章にしている
に過ぎません。
なので、事実を知って答えているというわけではなく、あくまで統計的にそれっぽい文章を組み立てている文章生成マシンでしかない、というわけですね。
このことをまず大前提として頭に入れておいた方がよいのです。
トークンとコンテキスト長
LLMで覚えておくべき項目としてトークンとコンテキスト長があります。
トークンはモデルが内部で扱う「細かい文字列の単位」です。
日本語だと1文字が1トークンになる場合もあれば、複数文字がまとめて1トークンになる場合もあります。
LLMはこのトークン単位で「次に来そうなトークン」を予測しながら文章を生成しています。
コンテキスト長はLLMが一度に覚えていられるトークン数の上限ですね。
LLMが一度に頭に乗せておけるトークン数の上限と思ってもらうとイメージしやすいかもです。
これまでの会話や、渡した文章・コードなどはすべてトークンに分割された上でモデルに渡されます。
その合計トークン数が、モデルのコンテキスト長を超えてしまうと、古い部分が切り捨てられることもあります。
そのため、会話が極端に長くなったり、ひとつのプロンプトで大量の仕様書やコードを入力させてしまうと、モデルが最初の方の前提を忘れたような振る舞いをすることがあることに注意を払っておくとよいですね。
LLMのクセと限界
実際にLLMを開発に使っていく上では、LLM特有のクセと限界を知っておくことも重要です。
ハルシネーション
LLMを開発で使っていると、ありそうなAPI名を自信満々に言ってきたけど存在しない、なんてことがたまにあります。
LLMはこういう「もっともらしいウソ」を平気で返してくることがあります。これがいわゆるハルシネーションですね。
ハルシネーションがなぜ起こるかというと、
- 事実をデータベースから引いているわけではなく、
- これまでの文脈から次に来そうなトークンを予測して出しているだけ
だからですね。なので知らないことを聞かれた時でもこれまでのパターンから「それっぽい答え」を組み立ててしまうのが怖いところですね。
知識のタイムラグ
また、LLMには「知識のタイムラグ」という問題もありますね。
LLMは、ある時点までに集められたテキストデータを使って学習されているので、
学習後に起きた出来事や、最近の仕様変更・法律改正などについては、そもそも知らないことがあります。
それでもやはり「それっぽい答え」を組み立ててしまうことがあるので、必ず公式ドキュメントや一次情報で確認する必要があります。
ただ、最新のChatGPTなどではWeb検索機能も備わってその場で最新情報を取りに行くことができるようになったので、この問題に関しては解消されつつあると言えます。
LLMの得意なこと
ここまで読むとLLMって使い方間違えると大変な仕事のミスにつながってしまいかねないですが、もちろんLLMの得意なこともあります。
代表的なのは、以下です。
- 文章の要約
- 文章の翻訳
- 言い換え(リライト)
- テキストからの構造化(箇条書きや表にする)
LLMは超ざっくり言うと、たくさんの文章を読ませて、この位置にはどの単語が来るかを当て続けるものなので、こういうテキストの形・構造・書き方を出すことには強いです。
そして、人間があらかじめ「事実となるテキスト」を渡してあげれば、LLMはそれを土台に、整理・要約・再構成することが得意です。ゼロから世界の真実を思い出す必要がない分、ハルシネーションも起きにくいというわけです。
逆に「この法律は2025年にどう改正された?」みたいなプロンプトの中に「正解の事実」が書いていない質問にはハルシネーションが起きやすいとも言えます。
まとめ
本記事ではちゃんとAIを学ぶ上での基礎知識として、AIの歴史とLLMの仕組みとクセまでについて解説してみました。
本記事を振り返ると、
- AIの流れは、 ルールベース → 機械学習 → ディープラーニング → LLM という系譜で進化してきた
- LLMは、 「次に来そうなトークン(単語)の確率を予測するディープラーニングモデル」 であり、 真実を知って正確に答えているのではなく、あくまで「文章生成マシン」である
- LLMにはハルシネーションや知識のタイムラグといったクセがある一方で、 要約・翻訳・言い換え・テキストの構造化・たたき台づくり といった 「テキスト → テキスト」の変換タスクは非常に得意
といった内容でした。
このあたりの前提を理解しておくと、AIに丸投げするのはキケンであり、AIに下ごしらえを任せて、最後は人間がチェックをする、という健康的なAIの使い方ができるのかと思います。
現場からは以上です!